Hi, I am a second-year Ph.D. student in Computer Science and Technology at Zhejiang University, advised by Asst. Prof. Chaochao Chen.
My research interests lie in trustworthy AI, with a specific focus on addressing privacy and ethical challenges in recommender systems and generative models through machine unlearning methods. Previously, I conducted research in federated representation learning.
We’ve released a curated literature repository on generative model unlearning, covering model families, unlearning objectives, methodologies, and evaluation protocols.
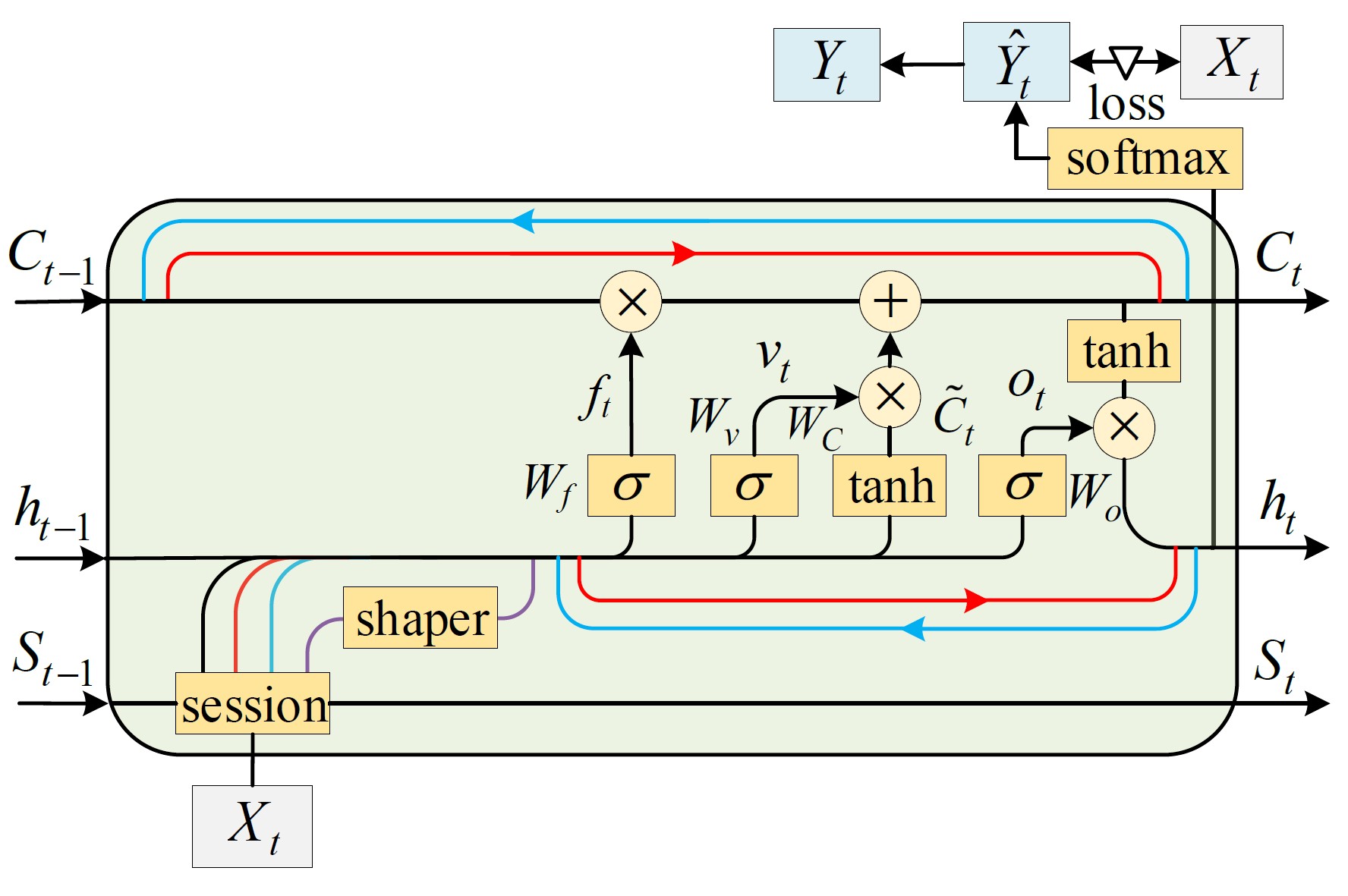
Traffic detection systems based on machine learning have been proposed to defend against cybersecurity threats, such as intrusion attacks and malware. However, they did not take the impact of network-induced phenomena into consideration, such as packet loss, retransmission, and out-of-order. These phenomena will introduce additional misclassifications in the real world. In this paper, we present \sf ERNN, a robust and end-to-end RNN model that is specially designed against network-induced phenomena. As its core, \sf ERNN is designed with a novel gating unit named as session gate that includes: (i) four types of actions to simulate common network-induced phenomena during model training; and (ii) the Mealy machine to update states of session gate that adjusts the probability distribution of network-induced phenomena. Taken together, \sf ERNN advances state-of-the-art by realizing the model robustness for network-induced phenomena in an error-resilient manner. We implement \sf ERNN and evaluate it extensively on both intrusion detection and malware detection systems. By practical evaluation with dynamic bandwidth utilization and different network topologies, we demonstrate that \sf ERNN can still identify 98.63% of encrypted intrusion traffic when facing about 16% abnormal packet sequences on a 10 Gbps dataplane. Similarly, \sf ERNN can still robustly identify more than 97% of the encrypted malware traffic in multi-user concurrency scenarios. \sf ERNN can realize \sim4% accuracy more than SOTA methods. Based on the Integrated Gradients method, we interpret the gating mechanism can reduce the dependencies on local packets (termed dependency dispersion). Moreover, we demonstrate that \sf ERNN possesses superior stability and scalability in terms of parameter settings and feature selection.
@article{zhao2023ernn,title={ERNN: Error-resilient RNN for Encrypted Traffic Detection Towards Network-Induced Phenomena},author={Zhao, Ziming and Li, Zhaoxuan and Jiang, Jialun and Yu, Fengyuan and Zhang, Fan and Xu, Congyuan and Zhao, Xinjie and Zhang, Rui and Guo, Shize},journal={IEEE Transactions on Dependable and Secure Computing},volume={},number={},pages={1--18},year={2023},month=feb,publisher={IEEE},doi={10.1109/TDSC.2023.3242134},url={https://ieeexplore.ieee.org/abstract/document/10036003},}
CVPR
Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Xinting Liao, Weiming Liu, Chaochao Chen*, Pengyang Zhou, Fengyuan Yu, and 5 more authors
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2024
Federated learning achieves effective performance in modeling decentralized data. In practice client data are not well-labeled which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However the performance of existing FUSL methods suffers from insufficient representations i.e. (1) representation collapse entanglement among local and global models and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2 we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets i.e. CIFAR10 and CIFAR100.
@inproceedings{liao2024rethinking,title={Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data},author={Liao, Xinting and Liu, Weiming and Chen, Chaochao and Zhou, Pengyang and Yu, Fengyuan and Zhu, Huabin and Yao, Binhui and Wang, Tao and Zheng, Xiaolin and Tan, Yanchao},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},pages={22841--22850},year={2024},month=jun,doi={10.1109/CVPR52733.2024.02155},url={https://openaccess.thecvf.com/content/CVPR2024/html/Liao_Rethinking_the_Representation_in_Federated_Unsupervised_Learning_with_Non-IID_Data_CVPR_2024_paper.html},}
NeurIPS
FOOGD: Federated Collaboration for Both Out-of-Distribution Generalization and Detection
Xinting Liao, Weiming Liu, Pengyang Zhou, Fengyuan Yu, Jiahe Xu, and 4 more authors
In Proceedings of the 38th International Conference on Neural Information Processing Systems , Dec 2024
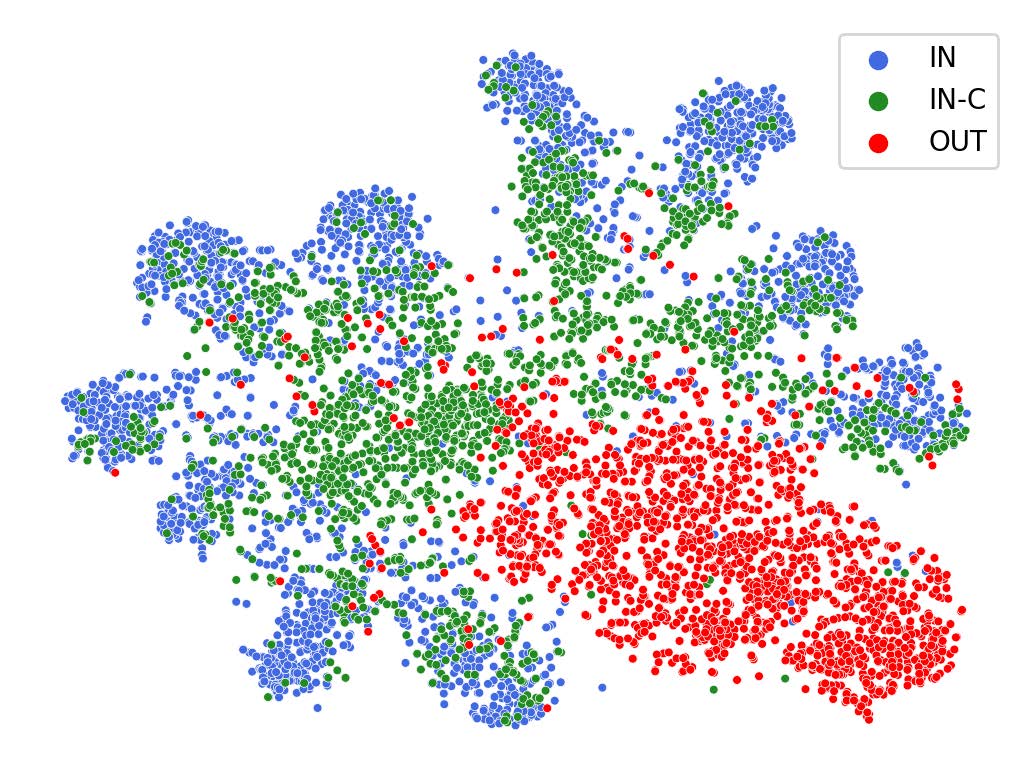
Federated learning (FL) is a promising machine learning paradigm that collaborates with client models to capture global knowledge. However, deploying FL models in real-world scenarios remains unreliable due to the coexistence of in-distribution data and unexpected out-of-distribution (OOD) data, such as covariate-shift and semantic-shift data. Current FL researches typically address either covariate-shift data through OOD generalization or semantic-shift data via OOD detection, overlooking the simultaneous occurrence of various OOD shifts. In this work, we propose FOOGD, a method that estimates the probability density of each client and obtains reliable global distribution as guidance for the subsequent FL process. Firstly, SM3D in FOOGD estimates score model for arbitrary distributions without prior constraints, and detects semantic-shift data powerfully. Then SAG in FOOGD provides invariant yet diverse knowledge for both local covariate-shift generalization and client performance generalization. In empirical validations, FOOGD significantly enjoys three main advantages: (1) reliably estimating non-normalized decentralized distributions, (2) detecting semantic shift data via score values, and (3) generalizing to covariate-shift data by regularizing feature extractor. The prejoct is open in https://github.com/XeniaLLL/FOOGD-main.git.
@inproceedings{liao2024foogd,title={FOOGD: Federated Collaboration for Both Out-of-Distribution Generalization and Detection},author={Liao, Xinting and Liu, Weiming and Zhou, Pengyang and Yu, Fengyuan and Xu, Jiahe and Wang, Jun and Wang, Wenjie and Chen, Chaochao and Zheng, Xiaolin},booktitle={Proceedings of the 38th International Conference on Neural Information Processing Systems},volume={37},pages={132908--132945},year={2024},month=dec,doi={10.48550/arXiv.2410.11397},url={https://proceedings.neurips.cc/paper_files/paper/2024/hash/efd1e27afcb94addd03b9e14c8d9f78f-Abstract-Conference.html},}
Survey
A Survey on Generative Model Unlearning: Fundamentals, Taxonomy, Evaluation, and Future Direction
Xiaohua Feng, Jiaming Zhang, Fengyuan Yu, Chengye Wang, Li Zhang, and 4 more authors
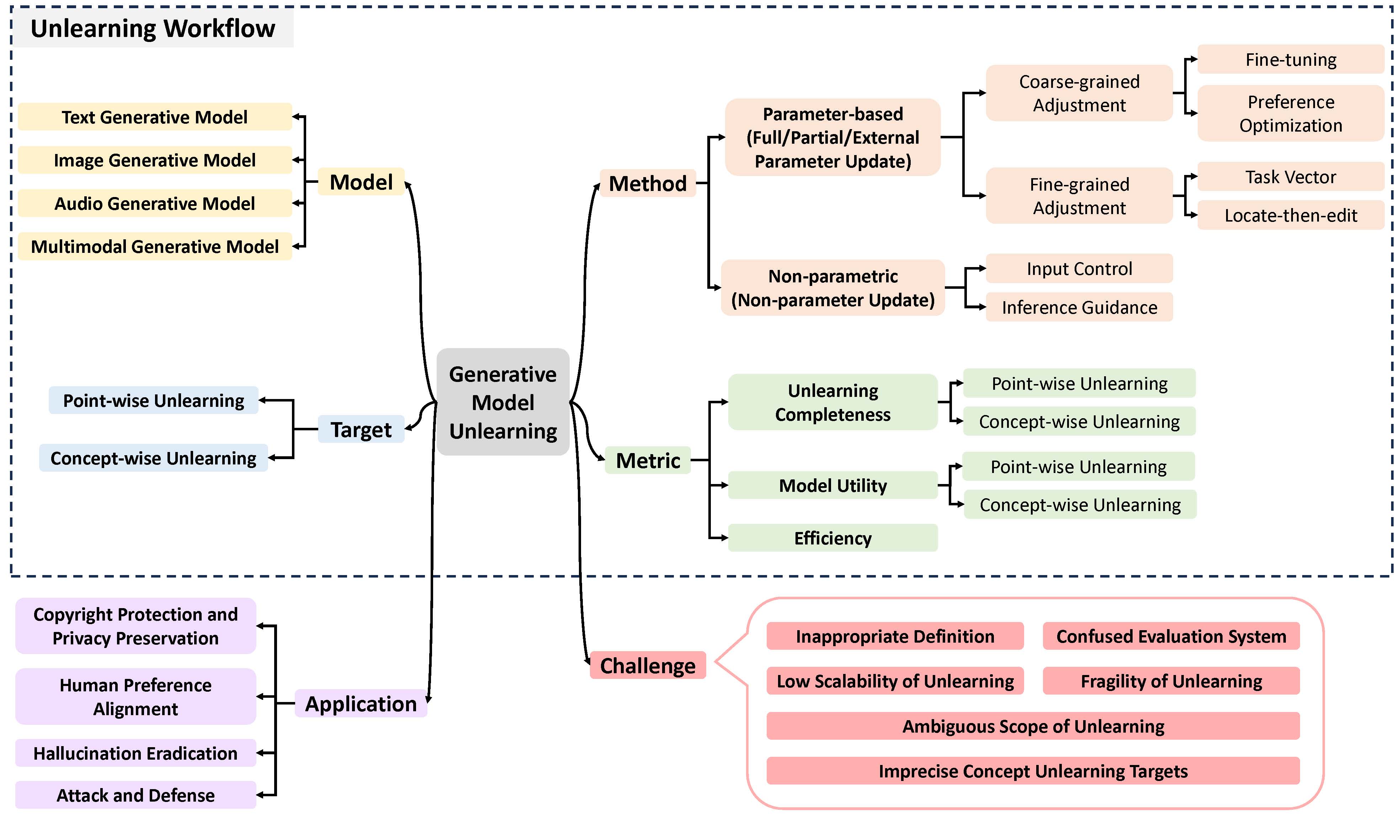
With the rapid advancement of generative models, associated privacy concerns have attracted growing attention. To address this, researchers have begun adapting machine unlearning techniques from traditional classification models to generative settings. Although notable progress has been made in this area, a unified framework for systematically organizing and integrating existing work is still lacking. The substantial differences among current studies in terms of unlearning objectives and evaluation protocols hinder the objective and fair comparison of various approaches. While some studies focus on specific types of generative models, they often overlook the commonalities and systematic characteristics inherent in Generative Model Unlearning (GenMU). To bridge this gap, we provide a comprehensive review of current research on GenMU and propose a unified analytical framework for categorizing unlearning objectives, methodological strategies, and evaluation metrics. In addition, we explore the connections between GenMU and related techniques, including model editing, reinforcement learning from human feedback, and controllable generation. We further highlight the potential practical value of unlearning techniques in real-world applications. Finally, we identify key challenges and outline future research directions aimed at laying a solid foundation for further advancements in this field. We consistently maintain the related open-source materials at this https URL.
@article{Feng2025GenMU,title={A Survey on Generative Model Unlearning: Fundamentals, Taxonomy, Evaluation, and Future Direction},author={Feng, Xiaohua and Zhang, Jiaming and Yu, Fengyuan and Wang, Chengye and Zhang, Li and Li, Kaixiang and Li, Yuyuan and Chen, Chaochao and Yin, Jianwei},journal={arXiv preprint arXiv:2507.19894},year={2025},month=jul,doi={10.48550/arXiv.2507.19894},url={https://arxiv.org/abs/2507.19894},eprint={2507.19894},archiveprefix={arXiv},primaryclass={cs.LG},}